配信

現代は情報爆発時代と呼ばれ、企業が取り扱うデータ量は指数関数的に増大し続けています。そして、ビッグデータ分析の重要性が増すなかで注目を集めているのが、膨大なデータを格納する「データレイク」です。本記事では、データレイクの概要について掘り下げるとともに、データウェアハウスとの違いや活用事例を解説します。

データ活用を阻む要因から理解する
データ活用に失敗しないためのポイント
データを活用しても様々な阻害要因によって成果に結びつかない企業が多いのが現状です。本資料では、そんなデータ活用に失敗しないためのポイントをご紹介します。
データレイクとは?
データレイクとは、すべての構造化データと非構造化データを一元的に保存可能な情報の格納庫を指します。XMLファイルやCSVファイルのような規則性のある構造化データや、文書データ、電子メール、画像ファイル、動画ファイルのような非構造化データなど、あらゆる情報をそのままの形式で格納するのが大きな特徴です。膨大なローデータを扱いやすいように泳がせておくことから「Data Lake(情報の湖)」と呼ばれています。
20世紀半ばに発明されたコンピュータは半世紀足らずで驚異的な進歩を遂げ、世の中に情報革命をもたらしました。しかし、IT化の恩恵を受けて経済が発展する一方で、市場競争性は激化の一途をたどっており、消費者ニーズは多様化かつ高度化しています。変化の加速する現代市場において、企業が競争優位性を確立するためには、膨大な経営データの効率的運用が欠かせません。このような社会的背景から、ビッグデータの分析基盤となるデータレイクが大きな注目を集めているのです。
データレイクとデータウェアハウスの違い
ともにビッグデータの分析基盤として利用される機会の多い、データレイクとデータウェアハウス。しかしその役割や目的には明確な違いがあります。
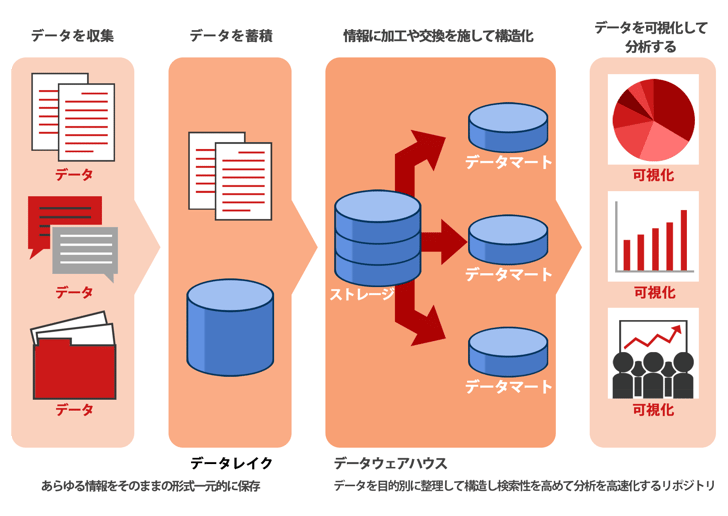
データ分析を実施する際は、情報を収集して蓄積し、分析することで可視化するというプロセスをたどるのが一般的です。データレイクはデータ形式や規模を問わずあらゆる情報を格納できるため、膨大なデータの収集と蓄積に長けています。しかし、集約されたデータを分析するためには、整理されていない膨大な情報を構造化しなくてはなりません。
そこで必要になるのが、情報に加工や変換を施して構造化するデータウェアハウスです。情報量が膨大であるほどデータの検索や分析に多大な時間を要します。データウェアハウスは、データを目的別に整理して構造化し、検索性を高めて分析を高速化するリポジトリです。データを分析しやすい状態で保管する倉庫のような役割を持つことから「Data Warehouse(情報の倉庫)」と呼ばれます。
データレイクのソリューションを挙げるなら、IBMの「IBM Cloud Pak for Data」や、Oracleの「Oracle Cloud Infrastructure Object Storage」などが代表的な製品です。データウェアハウスの代表的なソリューションとしては、Googleの「BigQuery」とAmazonの「Redshift」の2つが高いシェアを誇ります。
データレイクとデータウェアハウスは、それぞれが異なる特徴を持ち、どちらが優れていると比較するものではありません。企業の事業形態や経営戦略によって目的や役割が異なるシステムと言えるでしょう。
■データレイク
- データ構造:未加工のローデータ
- 利用目的:特定の目的をもたないあらゆるデータを収集・蓄積する
- 高コストの傾向がある
- 特徴:格納できるデータの多様性と柔軟性に富む
- ユーザー:データサイエンティスト等
■データウェアハウス
- データ構造:定義された構造化データ
- 利用目的:情報を構造化してデータ分析に最適化する
- 低コストの傾向がある
- 特徴:保管データの安全性と検索性に優れる
- ユーザー:ビジネスアナリスト等
データレイクの活用法
データ分析は、用途に合わせて情報を加工するのが一般的ですが、加工前のものを使用するケースもあります。加工されたデータは基本的に不可逆なため、何らかの処理を施すことでその後の分析に問題が生じる場合があるためです。したがって、構造化データしか保管できないデータウェアハウスは、情報の整理と分析には向いていても、収集と蓄積には不向きなリポジトリと言えるでしょう。
一方、データレイクは冒頭で述べたように、構造化データも非構造化データも同じように格納されます。このような特徴を持つことから、企業のあらゆる経営データを保管する格納庫としての活用が可能です。また、さまざまな形式のデータから多様な知見を引き出し、事業戦略や企画・開発の立案に用いることもできます。将来が予測しづらい昨今のビジネス環境において、データレイクが格納する情報の多様性と柔軟性に、多くの企業が注目しています。
データレイクのメリット
さまざまな形式の経営データを保管する格納庫として活用することで、事業部を横断した情報共有が可能となります。規模の大きな企業になるほど事業部も多くなり、各部門それぞれが業務データを管理するのが一般的です。
しかし、部門によって扱うデータ形式は異なり、さらに各部門に情報が散在していることで、事業部を跨ぐ情報共有や業務連携の遅滞を招くでしょう。データレイクはあらゆる形式のデータをそのままの状態で統合管理できるため、全社的な情報共有が可能になり、業務連携の円滑化と生産性向上に寄与します。
データレイクの導入事例
ここでは、実際にデータレイクを事業活動に取り入れ、自社の経営課題を解決した企業の事例を解説します。データレイクの導入によって、具体的にどのような成果を創出したのでしょうか。
株式会社リコー
株式会社リコーは、ファクシミリやレーザープリンターなどの事務機器や光学機器を製造するメーカーです。同社は経営データが各事業部に散在しており、部門を横断した情報共有が困難であるという経営課題を抱えていました。データがどこに保管されているのかもわからない状態では、事業部を跨いだデータを効率的に運用できません。そのため、組織全体の情報共有を円滑化すべく、「経営データを一元管理可能な基盤を構築すること」が急務となっていました。
そこで導入したのが、Amazonが提供するクラウドストレージサービス「Amazon S3」です。
Amazon S3は、構造化データ・非構造化データといった形態を問わず、あらゆるデータを容量無制限で格納できるという特徴を備えています。Amazon S3の導入によって情報の統合管理が可能になり、膨大な経営データを定量的に分析できる基盤が構築されました。経営データを可視化することで情報共有と業務連携が強化され、結果として意思決定のスピード向上や業務効率の改善につながったのです。
AGC株式会社
AGC株式会社は、1907年に創立された世界最大手のガラスメーカーです。長い歴史のなかで培われた技術力と生産力で、世界市場に向けて建築材料や化学関連素材を製造・販売してきました。
製造業界では、ドイツ政府主導のもとで「インダストリー4.0」が提唱され、AIやIoTの活用による技術革新が期待されています。同社も最先端のデジタル技術を活用すべく、運用基盤となるプラットフォームに「Amazon Web Services(以下AWS)」を選択します。
そして、論理的なデータ分析に基づくデータドリブン経営を目指し、AWSのクラウド環境上にデータレイクを構築しました。このAWS上に構築されたデータレイク環境は「VEIN」と名付けられ、全社共通のデータ活用基盤として、あらゆる情報の連携を実現させたのです。膨大な経営データ分析に集中できる環境を構築した結果、精度の高い需要予測や市場予測が可能となり、アジャイル開発や生産ラインの効率化や、経営貢献への意識改革に成功しました。
まとめ
テクノロジーの進歩によって、さまざまな産業が発展を遂げる一方で、企業が取り扱う情報量は増大し続けています。このような社会的背景のなか、企業が新たな市場価値を創出するためには、ビッグデータ分析を用いた経営戦略が欠かせません。データレイクはあらゆるローデータを格納するシステムであり、ビッグデータ分析に不可欠です。定量的なデータ分析に基づく経営戦略を構築するためにも、データレイクの導入を検討してみてはいかがでしょうか。
データ活用を阻む要因から理解するデータ活用に失敗しないためのポイント
データの活用は、顧客満足度の向上や意思決定の迅速化・正当化などの企業の 売上・利益に貢献する様々な効果があります。
本資料では、そんなデータ活用のポイントをご紹介します。